Однажды мне потребовалось решить такую задачку. Есть хранимая процедура. Требуется получить как можно более полную информацию о ее параметрах: имена, типы, значения по умолчанию. Необходимость в решении таких задач может возникнуть при создании приложений, в которых пользователи через конструкторы интерфейса самостоятельно создают отчеты.
Для извлечения требуемой информации лезем в системное представление sys.parameters. Тут представлена вся необходимая информация об именах параметров, их порядке, типах. Но вот про столбцы has_default_value и default_value в BOL сказано, что они заполняются только для объектов, созданных на базе clr. А что делать в этом случае с обычными хранимыми процедурами. Статья посвящена созданию группы функций и хранимых процедур, которые будут анализировать T-SQL-код хранимой процедуры, извлекая зашитые в коде значения параметров процедуры по умолчанию.
В коде хранимой процедуры могут встречаться самые разные синтаксические конструкции. Задача по их анализу, наверняка, чрезвычайно трудоемкая. В нашем случае, нам потребуется анализировать только незначительную часть всего богатства синтаксиса. А именно ту часть, которая находится "в окрестности" create proc. Посмотрим, что говорит BOL о синтаксисе create proc:
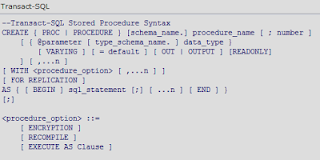
Нам необходимо проанализировать только малую часть кода процедуры: его начало, определение имени процедуры и ее параметров. Но и в этом случае для решения задачи потребуется написать более 700 строк sql-кода. В общем, чтобы новогодние каникулы были не очень скучными я решил написать небольшой парсер для анализа параметров процедуры. Итак, приступим.
Сперва создадим схему, которая будет содержать все необходимые объекты.
-- схема, содержащая объекты, необходимые для решения задач,
Еще нужна процедура, которая будет получать имя процедуры и возвращать ее код (обработка ошибок будет содержать в процедуре верхнего уровня, которая будет написана в конце):
Далее мы пойдем таким путем. Будет написано несколько функций и процедур. Перед каждой из них будет описываться их назначение и алгоритм. Функции и процедуры будут писаться в порядке, соответствующим общему алгоритму.
Анализ кода процедуры ("create proc ... ") будет происходить таким образом. Мы будет идти от начала строки кода процедуры, удаляя все лишние. Например, по ходу разбора строки кода мы дошли до слова "proc" (или "PROCEDURE"). Тогда его надо удалить, после чего алгоритм продолжит работу. То есть необходимо написать функцию, получающую в качестве параметра строку и число, и отсекающую от начала строки, поданной на вход, подстроку, длина которой совпадает со вторым параметром.
Не секрет, что имя объекта, если оно заключено в квадратные скобки или двойные кавычки может содержать любые символы (например, символ новой строки, табуляции). Даже, если имя объекта не заключено в скобки или кавычки, все равно оно может начинаться с любой буквы, входящей в список букв стандарт Unicode 3.2 (для MS SQL 2008 R2), например с японского иероглифа. Но вот ключевое слово Transact-SQL всегда начинается с большой или маленькой буквы латинского алфавита. В дальнейшем нам понадобится функция, которая определяет, начинается ли строка с символа однострочного или многострочного комментария, или же с символа, соответствующего букве латинского алфавита (в верхнем или нижнем регистре). Либо с какого-то иного символа.
Для извлечения требуемой информации лезем в системное представление sys.parameters. Тут представлена вся необходимая информация об именах параметров, их порядке, типах. Но вот про столбцы has_default_value и default_value в BOL сказано, что они заполняются только для объектов, созданных на базе clr. А что делать в этом случае с обычными хранимыми процедурами. Статья посвящена созданию группы функций и хранимых процедур, которые будут анализировать T-SQL-код хранимой процедуры, извлекая зашитые в коде значения параметров процедуры по умолчанию.
В коде хранимой процедуры могут встречаться самые разные синтаксические конструкции. Задача по их анализу, наверняка, чрезвычайно трудоемкая. В нашем случае, нам потребуется анализировать только незначительную часть всего богатства синтаксиса. А именно ту часть, которая находится "в окрестности" create proc. Посмотрим, что говорит BOL о синтаксисе create proc:

Нам необходимо проанализировать только малую часть кода процедуры: его начало, определение имени процедуры и ее параметров. Но и в этом случае для решения задачи потребуется написать более 700 строк sql-кода. В общем, чтобы новогодние каникулы были не очень скучными я решил написать небольшой парсер для анализа параметров процедуры. Итак, приступим.
Сперва создадим схему, которая будет содержать все необходимые объекты.
-- схема, содержащая объекты, необходимые для решения задач,
-- связанных с анализом строк
create schema Parser
authorization dbo
go
Еще нужна процедура, которая будет получать имя процедуры и возвращать ее код (обработка ошибок будет содержать в процедуре верхнего уровня, которая будет написана в конце):
--
процедура, возвращающая код процедуры по ее имени
create proc Parser.GetProcCode
(
@FullProcName nvarchar ( 1000
),
@code nvarchar ( max ) out
)
as
begin
set nocount, xact_abort on
declare @DBName nvarchar
( 200 ), @sql nvarchar ( max )
set @DBName = parsename ( @FullProcName, 3 )
set @sql = N'
select @code = [definition]
from ' + @DBName + '.sys.sql_modules
where [object_id] = object_id ( N''' + @FullProcName
+ ''', N''P''
)
'
exec sp_executesql
@sql,
N'@code nvarchar ( max ) out', @code = @code out
end
go
Далее мы пойдем таким путем. Будет написано несколько функций и процедур. Перед каждой из них будет описываться их назначение и алгоритм. Функции и процедуры будут писаться в порядке, соответствующим общему алгоритму.
Анализ кода процедуры ("create proc ... ") будет происходить таким образом. Мы будет идти от начала строки кода процедуры, удаляя все лишние. Например, по ходу разбора строки кода мы дошли до слова "proc" (или "PROCEDURE"). Тогда его надо удалить, после чего алгоритм продолжит работу. То есть необходимо написать функцию, получающую в качестве параметра строку и число, и отсекающую от начала строки, поданной на вход, подстроку, длина которой совпадает со вторым параметром.
-- "отсечение" от строки ее начала
create function Parser.EliminateStartStr
( @str
nvarchar (
max ),
@lenStr int
)
returns nvarchar ( max )
as
begin
return right ( @str, len ( @str ) - @lenStr )
end
go
Не секрет, что имя объекта, если оно заключено в квадратные скобки или двойные кавычки может содержать любые символы (например, символ новой строки, табуляции). Даже, если имя объекта не заключено в скобки или кавычки, все равно оно может начинаться с любой буквы, входящей в список букв стандарт Unicode 3.2 (для MS SQL 2008 R2), например с японского иероглифа. Но вот ключевое слово Transact-SQL всегда начинается с большой или маленькой буквы латинского алфавита. В дальнейшем нам понадобится функция, которая определяет, начинается ли строка с символа однострочного или многострочного комментария, или же с символа, соответствующего букве латинского алфавита (в верхнем или нижнем регистре). Либо с какого-то иного символа.
create function Parser.IsFirstLetterFromKeyWord
( @str
nvarchar (
max ) )
returns nvarchar ( 100 )
as
begin
if left ( @str, 2 ) = N'--'
return N'ComOneStr'
if left ( @str, 2 ) = N'/*'
return N'ComStr'
if unicode ( left ( @str, 1 ) ) between unicode ( N'a' ) and unicode ( N'z' ) or
unicode ( left ( @str, 1 ) ) between unicode ( N'A' ) and unicode ( N'Z' )
return N'Let'
return N'Symb'
end
go
В процессе отсечения от строки кода всего лишнего нам будет необходимо убедиться в том, что оставшаяся строка начинается с символа, который является началом либо ключевого слова. либо имени объекта, переменной, операции и т. д. В общем, необходимо уметь проверять, что строка начинается с чего-то такого, что в коде нельзя заменить на пробел. Это необходимо для того, чтобы в дальнейшем можно было отбросить однострочные или многострочные комментарии, а также пробельные символы. Сначала нужно узнать какие пробельные символы бывают. Например, мы пишем код: "create proc". Здесь мы соединяем ключевые слова "create" и "proc" пробелом. Вместо пробела можно было бы использовать и табуляцию и пустую строку. А что еще? Чтобы в точности все валидные символы, с помощью которых можно соединять слова напишем такой скрипт:
Выше выполняется цикл из 65536 итераций (по размеру типа nvarchar ( 1 )). На каждой итерации происходит формирование sql-выражения, которое является кодом на создание хранимой процедуры, в котором имя процедуры и ключевое слово "as" соединяются при помощи символа с кодом, равным итератору. С помощью блока try/catch проверяется синтаксис. Если код не попадает в catch, значит соответствующий символ нам нужен. Запустив код, можно лишний раз убедиться в том, что пробельными являются символы с кодами от 1 до 32. Теперь напишем функцию, с описания которой мы начали.
Предположим теперь, что строка начинается с однострочного комментария и его необходимо удалить. Воспользуемся тем, что символ новой строки имеет код равный 13.
create function Parser.EliminateOneStringComment ( @str nvarchar ( max ) )
Также нужна функция для удаления многострочного комментария:
Следующая функция похожа на предыдущую. Здесь также удаляются комментарии. Кроме того, удаляются пробельные символы. В общем функция ищет начала очередного символа в коде, для которого содержащее его слово нельзя заменить на пробел.
Процедура ниже предполагает, что строка начинается либо с однокомпонентного либо с двухкомпонентного имени объекта. Процедура убирает первую компоненту имени от строки и возвращает информацию о том, было ли имя двухкомпонентным. Алгоритм процедуры такой:
Следующая процедура использует все накопленные результаты для того чтобы от строки с кодом процедуры отсечь начальную часть вплоть до начала определения параметров.
declare @i int = 0, @sql nvarchar ( max ), @res int
while @i <= 65535
begin
--print
@i
set @sql = N'
if object_id ( N''dbo.testing'' ) is not
null
drop proc testing
'
exec sp_executesql
@sql
select @res = 0, @sql = N'create proc
testing' + nchar ( @i ) + N'as select
1'
begin try
exec sp_executesql
@sql
set @res =
0
end try
begin catch
--select error_message (),
@sql
set @res =
1
end catch
if @res =
0
begin
select @sql
print @i
end
set @sql = N'
if object_id ( N''dbo.testing'' ) is not
null
drop proc testing
'
exec sp_executesql
@sql
set @i +=
1
end
Выше выполняется цикл из 65536 итераций (по размеру типа nvarchar ( 1 )). На каждой итерации происходит формирование sql-выражения, которое является кодом на создание хранимой процедуры, в котором имя процедуры и ключевое слово "as" соединяются при помощи символа с кодом, равным итератору. С помощью блока try/catch проверяется синтаксис. Если код не попадает в catch, значит соответствующий символ нам нужен. Запустив код, можно лишний раз убедиться в том, что пробельными являются символы с кодами от 1 до 32. Теперь напишем функцию, с описания которой мы начали.
create function Parser.IsFirstLetterFromIdentifier
( @str
nvarchar (
max ) )
returns nvarchar ( 100 )
as
begin
declare @GapSymb table ( code int not null )
declare @MaxGapCode int
= 32
;
with Codes
as
(
select 1 as code
union all
select code +
1
from Codes
where code <= @MaxGapCode
)
insert into @GapSymb ( code )
select code
from Codes
if left ( @str, 2 ) = N'--'
return N'ComOneStr'
if left ( @str, 2 ) = N'/*'
return N'ComStr'
if unicode ( left ( @str, 1 ) ) in ( select code from @GapSymb )
return N'Gap'
return N'Symb'
end
go
create function Parser.EliminateOneStringComment ( @str nvarchar ( max ) )
returns nvarchar ( max )
as
begin
declare @i int = charindex ( nchar ( 13 ), @str, 1 )
return right ( @str, len ( @str ) - @i - 1 )
end
go
create function Parser.EliminateManyStringComment ( @str nvarchar ( max ) )
returns nvarchar ( max )
as
begin
declare @i int = charindex ( N'*/', @str, 1 )
return right ( @str, len ( @str ) - @i - 1 )
end
go
Следующая функция предполагает, что строка начинается с идентификатора, который заключен либо в двойные кавычки либо в квадратные скобки. Функция удаляет идентификатор. Используется критерий поиска конца идентификатора: он оканчивается на нечетное число кавычек либо скобок.
create function Parser.EliminateStringTillSymbol ( @str nvarchar ( max ), @Symb nvarchar ( 1 ) )
returns nvarchar ( max )
as
begin
declare @count int, @CurPos int = 1
set @CurPos = case when @Symb = N'[' then 1 else 2 end
set @count = 0
while 1 = 1
begin
if substring ( @str, @CurPos, 1 ) = @Symb
begin
set @count += 1
end
else
begin
set @count = 0
end
if @count % 2 = 1 and substring ( @str, @CurPos + 1, 1 ) <> @Symb
begin
return Parser.EliminateStartStr ( @str, @CurPos )
end
set @CurPos += 1
end
return N''
end
go
Следующая функция уже используется предыдущие. Она идет по строке, удаляя все комментарии и символы, с которых не может начинаться ключевое слово.
create function
Parser.EliminateTillKeyWord ( @str nvarchar ( max ) )
returns nvarchar ( max )
as
begin
declare @StartPosType
nvarchar ( 100 )
set @StartPosType
= 'Symb'
while @StartPosType
in ( N'ComOneStr', N'ComStr', N'Symb' )
begin
set @StartPosType
= Parser.IsFirstLetterFromKeyWord( @str )
if @StartPosType
= N'ComOneStr'
set @str = Parser.EliminateOneStringComment( @str )
if @StartPosType
= N'ComStr'
set @str = Parser.EliminateManyStringComment( @str )
if @StartPosType
= N'Symb'
set @str = Parser.EliminateStartStr ( @str, 1 )
end
return @str
end
go
create function Parser.EliminateTillIdentifier
( @str
nvarchar (
max ) )
returns nvarchar ( max )
as
begin
declare @StartPosType nvarchar
( 100 )
set @StartPosType =
'Gap'
while @StartPosType in ( N'ComOneStr', N'ComStr', N'Gap' )
begin
set @StartPosType =
Parser.IsFirstLetterFromIdentifier
( @str
)
if @StartPosType =
N'ComOneStr'
set @str = Parser.EliminateOneStringComment( @str )
if @StartPosType =
N'ComStr'
set @str = Parser.EliminateManyStringComment( @str )
if @StartPosType =
N'Gap'
set @str = Parser.EliminateStartStr(
@str, 1 )
end
return @str
end
go
- Сперва проверяем начинается ли строка с точки. Если это так, то удаляем точку и все последующие комментарии и пробельные символы и выходим (синтаксис допускает использование пробельных символов и комментариев между именем схемы и точкой, а также между именем объекта и точкой)
- Если строка начинается с символа кавычки или квадратной скобки, то имя объекта удаляется с помощью функции EliminateStringTillSymbol
- Если же имя объекта не обрамлено кавычками или скобками, то идет цикл по символам, из которых состоит имя объекта до тех пор пока не встретится один из пробельных символов или символ, с которого начинается комментарий или открывающаяся круглая скобка (на случай, если с этого места начинается перечень параметров). Также цикл прерывается, если встречается символ запятой или закрывающей круглой скобки (это связано с тем, что данная процедура будет использоваться для удаления из строки начальной подстроки, начинающейся с имени типа данных, за которым может следовать скобка, например, varchar(10) или decimal ( 30, 10 ) )
(
@str nvarchar ( max ) out,
@IsSchema bit out
)
as
begin
declare @GapSymb table ( code int not null )
declare @MaxGapCode int = 32
;
with Codes
as
(
select 1 as code
union all
select code + 1
from Codes
where code <= @MaxGapCode
)
insert into @GapSymb ( code )
select code
from Codes
declare @CurCode int, @LeftSymb nvarchar ( 1 ) = left ( @str, 1 )
set @CurCode = @MaxGapCode + unicode ( N'(' ) + unicode ( N'.' ) + 1
if @LeftSymb = N'.'
begin
set @str = Parser.EliminateStartStr ( @str, 1 )
set @str = Parser.EliminateTillIdentifier ( @str )
set @IsSchema = 1
return
end
if @LeftSymb = N'['
begin
set @str = Parser.EliminateStringTillSymbol ( @str, N']' )
end
if @LeftSymb = N'"'
begin
set @str = Parser.EliminateStartStr ( @str, 1 )
set @str = Parser.EliminateStringTillSymbol ( @str, N'"' )
end
if @LeftSymb not in ( N'.', N'[', N'"' )
begin
while @CurCode not in
(
select code
from @GapSymb
union all
select unicode ( N'(' )
union all
select unicode ( N'.' )
union all
select unicode ( N'/' )
union all
select unicode ( N'-' )
union all
select unicode ( N',' )
union all
select unicode ( N')' )
)
begin
set @str = Parser.EliminateStartStr ( @str, 1 )
set @CurCode = unicode ( left ( @str, 1 ) )
end
end
set @str = Parser.EliminateTillIdentifier ( @str )
if left ( @str, 1 ) = N'.'
begin
set @str = Parser.EliminateStartStr ( @str, 1 )
set @str = Parser.EliminateTillIdentifier ( @str )
set @IsSchema = 1
end
else
begin
set @IsSchema = 0
end
end
go
Следующая процедура использует все накопленные результаты для того чтобы от строки с кодом процедуры отсечь начальную часть вплоть до начала определения параметров.
create proc Parser.CutProcTillPrm
(
@str nvarchar ( max ) out
)
as
begin
declare @IsSchema bit
-- избавляемся от "create"
set @str = Parser.EliminateTillKeyWord( @str )
set @str = Parser.EliminateStartStr ( @str, len ( N'create' ) )
set @str = Parser.EliminateTillKeyWord ( @str )
-- избавляемся от "proc"
if lower ( left ( @str, len ( N'procedure' ) ) ) = lower ( N'procedure' )
begin
set @str = Parser.EliminateStartStr( @str, len ( N'procedure' ) )
end
else
begin
set @str = Parser.EliminateStartStr( @str, len ( N'proc' ) )
end
set @str = Parser.EliminateTillIdentifier ( @str )
-- избавляемся от имени схемы хранимой процедуры и от имени хранимой процедуры
-- (этот процесс удаляет также пробельные символы и комментарии между именем схемы и точкой и между точкой и именем процедуры)
exec Parser.EliminateObjectName @str out, @IsSchema out
if @IsSchema = 1
begin
exec Parser.EliminateObjectName @str out, @IsSchema out
end
set @str = Parser.EliminateTillIdentifier ( @str )
-- избавляемся от номера процедуры
if left ( @str, 1 ) = N';'
begin
set @str = Parser.EliminateStartStr ( @str, 1 )
set @str = Parser.EliminateTillIdentifier ( @str )
exec Parser.EliminateObjectName @str out, @IsSchema out
set @str = Parser.EliminateTillIdentifier ( @str )
end
if left ( @str, 1 ) = N'('
begin
set @str = Parser.EliminateStartStr ( @str, 1 )
set @str = Parser.EliminateTillIdentifier ( @str )
end
end
go
Теперь понадобится группа функций, которые будут отщеплять из начала строки значение параметра по умолчанию.
Сперва напишем функцию, которая сможет удалить из начала строки значение параметра, не заключенное в кавычки или скобки. То есть оно не может содержать и пробельных символов, а после него может идти только пробельный символ, или символ, с которого начинается комментарий, само же значение таких символов содержать не может (минус может содержаться только сначала для обозначения отрицательного числа).
create function Parser.GetSimpleStartWord ( @str nvarchar ( max ) )
Последняя процедура из текущей серии, вычисляющих значение параметра по умолчанию, реализует код, решающий задачу поиска и удаления значения параметра типа sysname, заключенного в квадратные скобки. Процедуре надо понять на каком месте заканчивается значение параметра. В качестве критерия используется такое соображение: точка окончания там, где есть нечетное число закрывающих квадратных скобок, после которого очередной закрывающей скобки уже нет.
Процедура FindOnePrmData предполагает, что строка начинается с имени параметра. В коде удаляется имя параметра (рассматривается случай двухкомпонентного имени типа параметра, а также наличие скобок после имени типа, например, в случае типа decimal и xml), а затем находится значение параметра по умолчанию с использованием трех последних процедур и функции. В процедуре FindOnePrmData есть еще выходной параметр, это требуется для того, чтобы отличить значение по умолчанию строкового параметра (или параметра типа sysname или clr-типа), равное строке default, от признака того, что этот параметр принимает значение, равное значению параметра по умолчанию для соответствующего типа данных. Также благодаря этому выходному параметру можно отличить текстовое значение null, заключенное в кавычки от пустого значения null.
Сперва напишем функцию, которая сможет удалить из начала строки значение параметра, не заключенное в кавычки или скобки. То есть оно не может содержать и пробельных символов, а после него может идти только пробельный символ, или символ, с которого начинается комментарий, само же значение таких символов содержать не может (минус может содержаться только сначала для обозначения отрицательного числа).
create function Parser.GetSimpleStartWord ( @str nvarchar ( max ) )
returns nvarchar ( max )
as
begin
declare @GapCodes table ( code int not null )
declare @CurCode int, @MaxGapCode int = 32, @CurLength int = 1
;
with Codes ( code )
as
(
select 0 as code
union all
select code + 1
from Codes
where code < @MaxGapCode
)
insert into @GapCodes ( code )
select code
from Codes
set @CurCode = @MaxGapCode + unicode ( N')' ) + unicode ( N',' ) + unicode ( N'/' ) + unicode ( N'-' ) + 1
while @CurCode not in
(
select code
from @GapCodes
union all
select unicode ( N',' )
union all
select unicode ( N')' )
union all
select unicode ( N'/' )
union all
select unicode ( N'-' )
) or ( @CurCode in ( unicode ( N'-' ) ) and @CurLength = 2 )
begin
set @CurCode = unicode ( substring ( @str, @Curlength, 1 ) )
set @CurLength += 1
end
return left ( @str, @CurLength - 2 )
end
go
Ниже следует процедура, решающая ту же задачу, что и предыдущая, но при условии, что значение параметра это строка, заключенная в одиночные или двойные кавычки (то есть тип данных параметра или строка или sysname). Я написал процедуру, а не функцию, поскольку нужно не только найти значение параметра, но и получить обновленную строку от которой отщепится значение параметра, чтобы можно было приступить к поиску значения значения по умолчанию для следующего параметра.
В предыдущей функции вычисляется значения параметра, не содержащее никаких кавычек, поэтому найдя параметр, можно, зная его длину, определить и что надо отщеплять от строки (что и будет сделано в дальнейшем). В нынешнем же случае, когда значение по умолчанию это строка, заключенная в кавычки, эта строка может содержать другие кавычки, которые удваиваются при написании такого строкового литарала в коде процедуры. Поэтому в процедуре при вычислении параметра все пары внутренних кавычек заменяются на одну. Так что проще всего написать не функцию, которая может вернуть только одно значение, а процедуру, имеющую 2 выходных параметра: параметр и оставшаяся часть строки:
create proc Parser.GetQuoteStartWord
(
@str nvarchar ( max ) out,
@Quote nvarchar ( 1 ),
@prmDefVal nvarchar ( max ) out
)
as
begin
declare @GapCodes table ( code int not null )
declare @CurPos int = 2, @LastLet nvarchar ( 1 ) = @Quote, @NextAfterLastLet nvarchar ( 1 ) = N'', @res nvarchar ( max ),
@CurQuoteCount int
set @CurQuoteCount = 0
while not
(
@CurQuoteCount % 2 = 1 and @NextAfterLastLet <>
@Quote
)
begin
set @LastLet = substring ( @str, @CurPos, 1 )
if @LastLet = @Quote
begin
set @CurQuoteCount += 1
end
else
begin
set @CurQuoteCount = 0
end
set @NextAfterLastLet
= substring ( @str, @CurPos + 1, 1 )
print @CurQuoteCount print @NextAfterLastLet
print @str
set @CurPos += 1
end
set @res = replace ( left ( @str, @CurPos - 1 ), @Quote + @Quote, @Quote )
set @str = Parser.EliminateStartStr ( @str, @CurPos - 1 )
set @res = left ( @res, len ( @res ) - 1 )
set @res = right ( @res, len ( @res ) - 1 )
set @prmDefVal = @res
end
go
create
proc Parser.GetStartWordInBrackets
(
@str nvarchar ( max ) out,
@prmDefVal nvarchar ( max ) out
)
as
begin
declare @CurSymb nvarchar ( 1 ), @NextSymb nvarchar ( 1 ), @ClosedBracketsCount int, @IsClosedBrStart bit, @Pos int = 1,
@res
nvarchar ( max )
set @IsClosedBrStart = 0
set @ClosedBracketsCount =
0
while 1 = 1
begin
set
@CurSymb = substring ( @str, @Pos, 1 )
if @CurSymb = N']'
begin
set
@IsClosedBrStart =
1
set
@ClosedBracketsCount +=
1
end
else
begin
set
@IsClosedBrStart =
0
set
@ClosedBracketsCount =
0
end
if @ClosedBracketsCount %
2 = 1 and substring ( @str, @Pos + 1, 1 ) <> N']'
begin
set
@res = left ( @str, @Pos )
set
@res = left ( @res, len ( @res ) - 1 )
set
@res = right ( @res, len ( @res ) - 1 )
set
@prmDefVal = replace ( @res, N']]', N']' )
set
@str = Parser.EliminateStartStr ( @str, @Pos )
return
end
set
@Pos += 1
end
end
go
create proc Parser.FindOnePrmData
(
@str nvarchar ( max ) out,
@prmDef nvarchar ( max ) out,
@HasOneQuote bit out
)
as
begin
set nocount, xact_abort on
declare @IsSchema bit, @Quote nvarchar ( 1 )
-- избавляемся от имени параметра
exec Parser.EliminateObjectName @str out, @IsSchema out
set @str = Parser.EliminateTillIdentifier ( @str )
-- избавляемся от имени схемы типа и от имени типа (заодно устраняются пробельные символы и комментарии между именем схемы типа и именем типа)
exec Parser.EliminateObjectName @str out, @IsSchema out
if @IsSchema = 1
begin
exec Parser.EliminateObjectName @str out, @IsSchema out
end
set @str = Parser.EliminateTillIdentifier ( @str )
-- удалить возможные скобки
if left ( @str, 1 ) = N'('
begin
-- удаляем скобку
set @str = Parser.EliminateStartStr ( @str, len ( N'(' ) )
set @str = Parser.EliminateTillIdentifier ( @str )
-- удаляем: либо имя коллекции схем xml либо цифры (масштаба)
exec Parser.EliminateObjectName @str out, @IsSchema out
if @IsSchema = 1
begin
exec Parser.EliminateObjectName @str out, @IsSchema out
end
set @str = Parser.EliminateTillIdentifier ( @str )
-- удаляем точность (если она есть)
if left ( @str, 1 ) = N','
begin
set @str = Parser.EliminateStartStr ( @str, len ( N',' ) )
set @str = Parser.EliminateTillIdentifier ( @str )
exec Parser.EliminateObjectName @str out, @IsSchema out
set @str = Parser.EliminateTillIdentifier ( @str )
end
-- удаляем обратную скобку
if left ( @str, 1 ) = N')'
begin
set @str = Parser.EliminateStartStr ( @str, len ( N')' ) )
set @str = Parser.EliminateTillIdentifier ( @str )
end
end
if lower ( left ( @str, len ( N'varying' ) ) ) = lower ( N'varying' )
begin
set @str = Parser.EliminateStartStr ( @str, len ( N'varying' ) )
set @str = Parser.EliminateTillIdentifier ( @str )
end
if left ( @str, 1 ) <> N'='
begin
set @prmDef = null
return
end
else
begin
set @str = Parser.EliminateStartStr ( @str, 1 )
set @str = Parser.EliminateTillIdentifier ( @str )
if left ( @str, 1 ) not in ( N'''', N'"', N'[' )
begin
set @prmDef = Parser.GetSimpleStartWord ( @str )
set @str = Parser.EliminateStartStr ( @str, len ( @prmDef ) )
end
else
begin
set @HasOneQuote = 1
end
if left ( @str, 1 ) in ( N'"', N'''' )
begin
set @Quote = left ( @str, 1 )
exec Parser.GetQuoteStartWord @str out, @Quote, @prmDef out
end
if left ( @str, 1 ) in ( N'[' )
begin
exec Parser.GetStartWordInBrackets @str out, @prmDef out
end
end
end
go
Ну а теперь соберем результаты работы последних процедур воедино и напишем процедуру, которая идет в цикле по параметрам и вычисляет их значения по умолчанию, там где они есть. Попутно, возможно придется убирать не только пробельные символы и комментарии, но и некоторые ключевые слова (readonly, out, output).
Ну и теперь сама общая процедура, решающая всю задачу:
create proc Parser.FindAllDefaultValues
(
@str nvarchar ( max ),
@PrmCount int
)
as
begin
set nocount, xact_abort on
declare @curPrm int = 1, @prmVal nvarchar ( max ), @DistTillVar int, @CurOper int = 1,
@HasOneQuote bit
declare @PrmDefData table ( number int, value nvarchar ( max ), HasOneQuote bit )
while @curPrm <= @PrmCount
begin
set @CurOper = 1
if @curPrm <> 1
begin
while @CurOper <= 3 -- число элементов, которые могут идти после значения по умолчанию до следующего параметра
-- (ключевые слова out, readonly, запятая)
begin
set @str = Parser.EliminateTillIdentifier ( @str )
if left ( @str, len ( N',' ) ) = N','
begin
set @str = Parser.EliminateStartStr ( @str, len ( N',' ) )
end
if lower ( left ( @str, len ( N'output' ) ) ) = lower ( N'output' )
begin
set @str = Parser.EliminateStartStr ( @str, len ( N'output' ) )
end
if lower ( left ( @str, len ( N'out' ) ) ) = lower ( N'out' )
begin
set @str = Parser.EliminateStartStr ( @str, len ( N'out' ) )
end
if lower ( left ( @str, len ( N'readonly' ) ) ) = lower ( N'readonly' )
begin
set @str = Parser.EliminateStartStr ( @str, len ( N'readonly' ) )
end
set @str = Parser.EliminateTillIdentifier ( @str )
if left ( @str, 1 ) = N'@'
break
set @CurOper += 1
end
end
set @HasOneQuote = null
exec Parser.FindOnePrmData @str out, @prmVal out, @HasOneQuote out
insert into @PrmDefData ( number, value, HasOneQuote )
values ( @curPrm, @prmVal, @HasOneQuote )
set @curPrm += 1
end
select number, value, HasOneQuote
from @PrmDefData
end
go
create proc Parser.GetProcPrmDefaultValues
(
@FullProcName nvarchar ( 1000 )
)
as
begin
set nocount, xact_abort on
declare @code nvarchar ( max ), @prmCount int, @sql nvarchar ( max )
if parsename ( @FullProcName, 1 ) is null or
parsename ( @FullProcName, 2 ) is null or
parsename ( @FullProcName, 3 ) is null
begin
raiserror ( N'Имя процедуры не является трехкомпонентным.', 16, 1 )
return
end
if object_id ( @FullProcName, N'P' ) is null
begin
raiserror ( N'Не найдена процедура с именем "%s".', 16, 1, @FullProcName )
return
end
exec Parser.GetProcCode @FullProcName, @code out
set @sql = N'
select
@prmCount = count (*)
from ' + quotename ( parsename ( @FullProcName, 3 ) ) + '.sys.parameters
where
[object_id] = object_id ( N''' + @FullProcName + ''', N''P'' )
'
exec sp_executesql @sql, N'@prmCount int out', @prmCount = @prmCount out
if @prmCount = 0
begin
select N'' name, N'' value
where 1 = 0
return
end
exec Parser.CutProcTillPrm @code out
if object_id ( N'tempdb..#prmDefData',
N'U' ) is not null
drop table #prmDefData
create table #prmDefData
(
number int not null,
value nvarchar ( max ) null,
HasOneQuote bit null,
primary key clustered ( number asc )
) on [PRIMARY]
insert into #prmDefData ( number, value, HasOneQuote )
exec Parser.FindAllDefaultValues @code, @prmCount
set @sql = N'
select
prm.name, data.value, data.HasOneQuote
from
' + quotename ( parsename ( @FullProcName, 3 ) ) + '.sys.parameters prm
inner
join
#prmDefData
data on prm.parameter_id = data.number
where
prm.[object_id] = object_id ( N''' + @FullProcName + ''', N''P'' )
'
exec sp_executesql @sql
end
go